Learning to Synthesize a 4D RGBD Light Field from a Single Image
Pratul P. Srinivasan, Tongzhou Wang, Ashwin Sreelal, Ravi Ramamoorthi, Ren Ng
Published in ICCV 2017
Abstract:
- 制作了一个最大的光场数据集,包含约 3300 张光场图像
- 两个 CNN 分别用于预测场景的深度信息,以及预测 occluded rays and non-Lambertian effects
- 基于最近的视合成方法, 创新点在于可以预测每条光线的 RGBD (也就是说从既可以预测光线的颜色,也可以估计深度),并利用光线的视差一致性提升了单个 view 的深度估计
Introduction:
利用非监督学习框架估计场景深度
LOSS 为利用估计的场景深度和 center view 渲染得到的光场,再经过对遮挡区域和 non-Lambertain 场景增强修复后,与真实光场之间的差异
框架(从单个 view 到 4D LF 分为三个子任务,详细解释见下文):

Related Work
- Light Fields
- View Synthesis from Light Fields
- View Synthesis without Geometry Estimation
- View Synthesis by Geometry Estimation
- 3D Representation Inference from a Single Image
Light Field Synthesis
- 定义从单个 view 估计 4D Light Field 的映射为 \(f\)
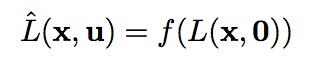
\(f\) 分解为三个子步骤:1.利用 CNN 从 center view 估计所有 view 的深度图 2.从深度图和 center view warping 出所有 view 3. 使用另一个 CNN 计算残差来修复遮挡和 non-Lambertain 失真,并与步骤 2 的输出相加
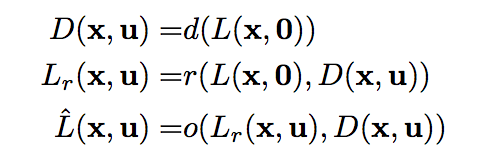 \(D,L,L_r,\hat{L}\) 分别是,估计的深度图,训练光场数据,利用 center view 和深度图合成的光场,加上残差来修复遮挡和 non-Lambertain 失真后的光场
\(D,L,L_r,\hat{L}\) 分别是,估计的深度图,训练光场数据,利用 center view 和深度图合成的光场,加上残差来修复遮挡和 non-Lambertain 失真后的光场损失函数
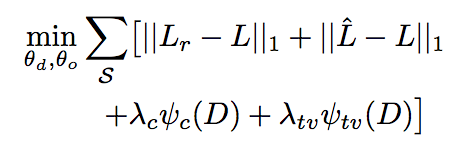 \(\psi_c,\psi_{tv}\)是两个正则项,后面会介绍
\(\psi_c,\psi_{tv}\)是两个正则项,后面会介绍损失函数中包含 \(L,L_r\) 的误差项是为了防止遮挡预测网络自己学习使得深度估计网络无法学习到一个合适的深度估计函数
Light Field Dataset
- 目前为止(2017.9)最大的光场数据集(总共 3343 :3243 用于训练,100 用于测试)
- 利用 Lytro Illum 采集,固定焦距 30mm,光圈 f/2 ,其他参数自动
- 利用 Lytro Power Tools Beta 解码
- 分辨率 376x541x14x14,只采用中间 8x8 的 view
- 数据集场景主要为 花和植物
Synthesizing 4D Ray Depths
在纹理较少的区域,即使深度估计错误,基于深度的 warping 仍旧可以合成正确的 view
遮挡边界处的深度估计往往是不正确的,因为预测正确的深度需要从遮挡处采集像素
如果只考虑视合成,那么错误的深度没有很大的影响,但是,如果将视合成看成是一个从单个 2D view 的估计深度的非监督学习算法,那么就需要提升预测的深度图的准确度
考虑到不同 view 之间视差一致性,在同一个 slope 上的点深度相同,所以
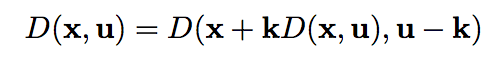 取 \(k = 1\) ,得到一个正则项
取 \(k = 1\) ,得到一个正则项 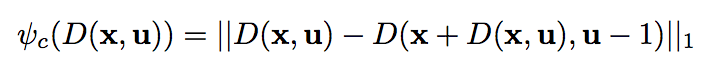 又因为错误的深度会导致更大的梯度,所以在采用一个关于梯度的正则项
又因为错误的深度会导致更大的梯度,所以在采用一个关于梯度的正则项 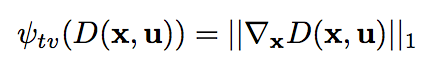
深度估计网络 采用 dilated convolution,batch normalization,exponentially linear unit activation,输出层使用 scaled tanh activation ([-16,16])
Synthesizing the 4D Light Field
Lambertian Light Field Rendering
 输入 center view 和各个 view 的深度图,warping 得到所有 view
输入 center view 和各个 view 的深度图,warping 得到所有 viewOcclusions and Non-Lambertian Effects 输入 \(L_r, D\) 利用 CNN 输出一个残差修正项 5 层 3D CNN,batch normalization, ELU activation, 输出采用 tanh activation([-1,-1])
Training
- 训练样本从数据集中随机剪裁出 192x192x8x8 的局部光场,再下采样为 96x96x8x8
- 基于深度的 view 合成采用 bilinear interpolation,所以网络是全可微分的
- 训练方法采用 first-order Adam optimization algorithm
Results
深度估计结果与 Accurate depth map estimation from a lenslet light field camera. In CVPR, 2015 做了对比在许多场景中有更好的细节
视合成结果与 View synthesis by appearance flow. In ECCV, 2016 做了对比,在边缘还原上效果更好,并且在测试集上误差的分布更好
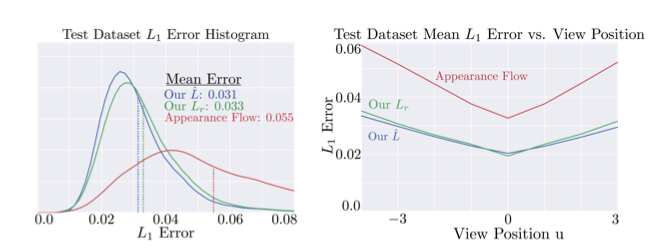
作者尝试了用 appearance flow 生成 view 的方法,只需将深度估计网络的改成预测 flow fields 来生成各个 view,因为 appearance flow 不能生成明确的几何表示,所以不能被用于深度估计
直观上来说, 将观察到的光线流入遮挡区域的正确的策略会随着不同的花的颜色和形状而动态地改变,所以难以学习。作者将问题分成了深度预测和被遮挡的光线预测,所以深度预测网络可以专注于深度估计的正确性,不需要正确的预测被遮挡的光线
作者还尝试了用一个深层网络直接从 center view 预测 4D 光场,平均误差为 0.036
本文方法还与与 Learning-based view synthesis for light field cameras. In ACM Transactions on Graphics, 2016 对比,本文方法平均误差比上面的工作更大
展示了合成的光场图像在 EPI 有比较复杂的纹理,而且具有一定的 refocus 效果
Conclusion
- 论证泛化效果,作者演示了用手机相机拍摄的一个场景生成的光场图像的深度图,EPI,以及 refocus 效果
- 在一个玩具汽车上尝试了泛化(感觉效果一般)